
Por J. Daniel Aromí *
Las crisis de deuda soberana constituyen un tipo de evento recurrente de gran relevancia. Así lo demuestran diversos episodios ampliamente documentados.[1] Frente a estos eventos surgen dos tipos de preguntas relacionadas. El primer conjunto de cuestiones tiene que ver con la descripción y explicación de estos fenómenos ¿En qué circunstancias ocurren las crisis de deuda soberana? ¿Cuáles son las causas? ¿Se deben a ignorancia, mala suerte u oportunismo? La segunda clase de preguntas tiene que ver con nuestra capacidad para anticipar este tipo de eventos ¿Es posible predecir una crisis de deuda soberana? ¿Con cuántos años de antelación se puede predecir una crisis con un nivel aceptable de precisión? ¿Cuáles son las señales o circunstancias que permiten anticipar una crisis?
Existe una amplia literatura que intenta avanzar respuestas a estas preguntas. Con respecto a los primeros interrogantes, entre las causas de las crisis se ha apuntado a la llegada de shocks reales que golpean adversamente a la economía[2], errores en la percepción de las potencialidades de la economía de un país[3], fluctuaciones en los niveles de confianza en el sistema financiero[4] y oportunismo por parte del deudor[5]. La existencia de estas diversas explicaciones sugiere que el estudio de este tipo de eventos requiere la consideración de un amplio conjunto de aspectos potencialmente relevantes.
Con respecto al segundo tipo de cuestiones existen múltiples estudios que evalúan la capacidad para anticipar crisis económicas en general y crisis de deuda soberana en particular. Esta literatura establece una asociación entre eventos de crisis y variables relacionadas a niveles de solvencia, liquidez, tipo de cambio real y contexto macroeconómico.[6]
Naturalmente, el objetivo de esta nota no es resolver una cuestión compleja que lleva muchos años de discusión. Más humildemente, a continuación, se discutirá el potencial de una herramienta pocas veces utilizada en economía. Es en este contexto donde las crisis de deuda se intersectan con los árboles o los bosques.
Los árboles pueden brindar respuestas
Los árboles de clasificación constituyen un tipo de herramienta estadística que identifica patrones de asociación entre variables de interés a través de una secuencia de particiones del espacio de variables explicativas.[7] Estas técnicas han sido utilizadas con éxito en diversas áreas del conocimiento como meteorología, astronomía, medicina, biología molecular y psicología.
Para describir la herramienta, tiene sentido pensar en el problema de interés. En el contexto aquí planteado, el objetivo consiste en establecer asociaciones entre la ocurrencia de crisis de deuda soberana y un conjunto de aspectos o variables explicativas que, en principio, se consideran relevantes. Las variables explicativas podrían estar dadas por indicadores de niveles de deuda externa, activos externos netos, saldo de cuenta corriente, niveles de reservas internacionales, tipo de cambio real, trayectoria macroeconómica reciente o niveles de inversión. A partir de un conjunto de datos, el árbol de clasificación identifica particiones del espacio de las variables explicativas según su asociación con la ocurrencia de crisis. Por ejemplo, la herramienta podría identificar rangos de valores para la deuda externa y las reservas internacionales que combinados identifican escenarios asociados a alta incidencia de crisis de deuda soberana.
Un árbol de clasificación es construido en forma secuencial. El primer paso consiste crear una partición del espacio eligiendo una variable y un valor crítico para esta variable. La partición generada es la que, de acuerdo a un criterio prestablecido, maximiza la capacidad para distinguir entre escenarios asociados a baja o alta incidencia de crisis. Luego de la primera partición, se aplica el mismo procedimiento a cada uno de los sub-espacios resultantes. El algoritmo continúa de esta manera hasta el punto en que se advierte que la partición no agrega suficiente información.
Esta metodología establece asociaciones no-lineales y puede ser aplicada en el caso de gran número de variables explicativas. Adicionalmente, los árboles de clasificación permiten la evaluación de la información de cada variable según el contexto. Por último, entre sus aspectos deseables se encuentra la posibilidad de interpretar los resultados con gran naturalidad.
Ejemplo: un árbol sobre las crisis
A continuación se muestra un ejercicio exploratorio que aplica la metodología antes descripta al análisis de crisis de deuda soberana.[8] El gráfico 1 muestra un árbol que identifica asociaciones entre condiciones económicas e incidencia de crisis en los cinco años posteriores.[9] Se consideraron 15 variables explicativas relacionadas con niveles de liquidez, solvencia, apalancamiento, desempeño económico y apreciación del tipo de cambio real. El gráfico resultante muestra cinco nodos en los que se implementa una división del espacio que desembocan en seis escenarios o nodos finales.
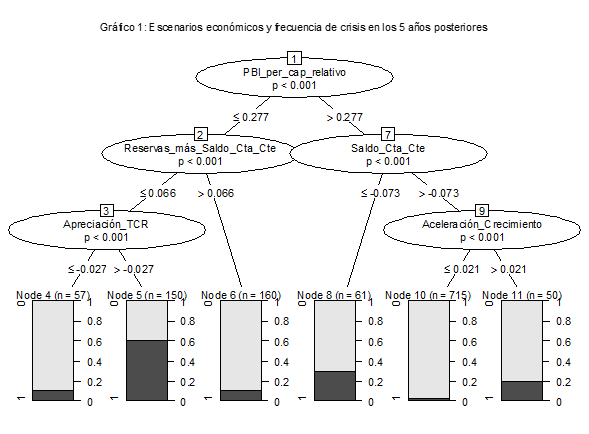
En la primera partición se selecciona el PIB per cápita en relación al de EEUU. Si el PIB per cápita está por debajo (arriba) de 28% del PIB per cápita de EEUU el escenario es asociado a una alta (baja) incidencia de crisis. Siguiendo la primera rama, para el caso de bajo PIB per cápita, el algoritmo ejecuta una nueva partición que depende de un indicador de liquidez. De acuerdo a esta segunda partición, el nivel de incidencia de crisis depende de la suma de las Reservas Internacionales y el Saldo de la Cuenta Corriente. Bajos niveles, menores al 6,6% del PIB, son asociados a una mayor incidencia de crisis. Subsiguientemente, para países de bajo PIB per cápita y bajos niveles de liquidez, se aplica una nueva separación que depende de la apreciación del tipo de cambio. En forma similar, el sub-espacio de alto PIB per cápita es subdividido en dos instancias según el nivel del saldo de Cuenta Corriente y una aceleración en el crecimiento del PIB a precios constantes.
De esta manera, este ejercicio exploratorio resulta en un árbol de clasificación que ofrece una descripción informativa de los escenarios asociados a crisis. En particular, países con ingresos relativamente bajos, con baja liquidez y tipo de cambio relativamente apreciado están asociados a una muy alta incidencia de crisis. Para este escenario, la frecuencia de crisis en los siguientes 5 años es aproximadamente 60%. Vale la pena notar que el algoritmo podría haber elegido pero no eligió variables que miden niveles de endeudamiento o de activos netos. Este resultado puede ser utilizado a la hora de evaluar la relevancia relativa de distintas explicaciones.
De acuerdo a lo esperado, en el caso de los países con mayores ingresos, la incidencia de crisis es menor. De todas maneras, según el árbol de clasificación, existen dos escenarios en los que la incidencia de crisis es no menor. Tanto en el caso de un importante déficit en cuenta corriente (mayor a 7%) como en el caso de aceleración en la tasa de crecimiento (ocho años con crecimiento 2% por arriba a la tendencia histórica), se observan frecuencias de entre 30% y 20%.
Nuevamente, corresponde aclarar que el algoritmo seleccionó variables asociadas a niveles de liquidez pero no seleccionó las variables que miden niveles de endeudamiento o activos internacionales netos. Adicionalmente se observa que la selección de variables como apreciación real o aceleración de crecimiento son compatibles con la imagen de economías que experimentan expansiones vulnerables o insostenibles. Si bien estas observaciones no son concluyentes, los resultados sugieren que nuestra comprensión de las crisis de deuda podría verse favorecida por este tipo de ejercicio.
Que el árbol no oculte el bosque
Un problema con el uso de árboles de clasificación es que resulta difícil identificar cuán robusto es el resultado encontrado. Por ejemplo, es factible que el árbol construido ignore variables con información valiosa o le otorgue excesivo protagonismo a alguna variable no muy informativa. Si bien los errores de inferencia constituyen un elemento inherente a todo ejercicio estadístico, en este caso el problema puede llegar acentuarse debido a la secuencialidad y no-linealidad del método bajo consideración. Frente a estas observaciones, una solución puede tener que ver con usar más, y no menos, árboles. En esta dirección, se encuentra la metodología llamada “bosques aleatorios”.[10]
Bajo esta alternativa se implementa un tipo de ejercicio comúnmente conocido como bootstrap. En primer lugar, se extraen en forma aleatoria observaciones de la base de datos original para construir nuevas bases de datos artificiales. Luego, para cada una de estas bases de datos artificiales, se elige aleatoriamente un subconjunto de variables explicativas y se computa los árboles de clasificación asociados. Finalmente, los árboles resultantes son combinados para obtener una nueva descripción de las asociaciones entre las variables explicativas y las respuestas. La conjetura subyacente es que la elección aleatoria de observaciones y variables permite establecer vínculos más robustos que dependen en menor medida de accidentes en el muestreo o la selección de variables.
Mientras que los árboles de clasificación surgen como una interesante herramienta para explicar o describir eventos de crisis, los bosques aleatorios lucen particularmente valiosos para ejercicios de pronóstico. De todas maneras, en principio, no existen motivos concluyentes para preferir esta metodología frente a un modelo más tradicional (OLS, logit) o frente a otras alternativas poco tradicionales (“k vecinos más cercanos”, máquinas vectores soporte, etc). Incluso, es factible que elegir entre modelos sea subóptimo. Según algunos investigadores, lo óptimo es aprender a combinar pronósticos que surgen de distintas metodologías.[11] Es decir, practicar un poco de alquimia.
* Ph.D. in Economics, University of Maryland at College Park. Master en Economía, Universidad de San Andrés. Es Investigador del Instituto Interdisciplinario de Economía Política (IIEP-Baires) y se desempeña también como docente de grado y de posgrado en diversas universidades del país. Su principal área de interés es la economía conductual y sus aplicaciones.
[1] Kindleberger y O’Keefe (2001), Reinhart y Rogoff (2009).
[2] Arellano (2008)
[3] Heymann y Sanguinetti (1998)
[4] Desde distintas perspectivas este argumento puede ser asociado a Misnky (1992) y Calvo (1998).
[5] Meltzer (2000).
[6] Algunos ejemplos recientes están dados por los trabajos de Manasse y Roubini (2009), Frankel y Saravelos (2012) y Catão y Milesi-Ferreti (2014). Metodológicamente Manasse y Roubini (2009) es el más cercano a lo aquí expuesto.
[7] Para una descripción más detallada de estas técnicas ver Breiman et al. (1984) y Strobl et al. (2009).
[8] Se utilizó el paquete “party” de la plataforma R.
[9] Los datos utilizados coinciden en gran medida con los utilizados por Catão y Milesi-Ferretti (2014). Cubren 73 países y el período 1970-2011. El ejercicio sólo considera la predicción para países que, al momento del pronóstico, tenían acceso al mercado de deuda, es decir, no estaban en crisis.
[10] Breiman (2001).
[11] Woźniak (2014)
Referencias:
Arellano, C. (2008). Default risk and income fluctuations in emerging economies. The American Economic Review, 98(3), 690-712.
Breiman, Leo; Friedman, J. H.; Olshen, R. A.; Stone, C. J. (1984). Classification and regression trees. Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software
Breiman, L. (2001). Random forests. Machine learning, 45(1), 5-32.
Catão, L. A., & Milesi-Ferretti, G. M. (2014). External liabilities and crises.Journal of International Economics, 94(1), 18-32.
Calvo, G. A. (1988). Servicing the public debt: The role of expectations. The American Economic Review, 647-661.
Frankel, J., & Saravelos, G. (2012). Can leading indicators assess country vulnerability? Evidence from the 2008–09 global financial crisis. Journal of International Economics, 87(2), 216-231.
Heymann, D., & Sanguinetti, P. (1998). Business cycles from misperceived trends. ECONOMIC NOTES-SIENA-, 205-232.
Hothorn, T., Bühlmann, P., Dudoit, S., Molinaro, A., & Van Der Laan, M. J. (2006). Survival ensembles. Biostatistics, 7(3), 355-373.
Kindleberger, C. P., & O’Keefe, R. (2001). Manias, panics, and crashes. Palgrave Macmillan.
Manasse, P., & Roubini, N. (2009). “Rules of thumb” for sovereign debt crises.Journal of International Economics, 78(2), 192-205.
Meltzer, A. (2000). Report of the international financial institutions advisory commission. Washington, DC.
Minsky, H. P. (1992). The financial instability hypothesis. The Jerome Levy Economics Institute Working Paper, (74).
Reinhart, C. M., & Rogoff, K. (2009). This time is different. Eight Centuries of Financial Folly, Princeton University, Princeton and Oxford.
Strobl, C., Malley, J., & Tutz, G. (2009). An introduction to recursive partitioning: rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychological methods, 14(4), 323.
Woźniak, M., Graña, M., & Corchado, E. (2014). A survey of multiple classifier systems as hybrid systems. Information Fusion, 16, 3-17.

Excelente post. Hace unos dias que estoy trabajando con el caso de China y las dudas que hay respecto de su futuro y me sirve mucho este abordaje para salir de los enfoques más tradicionales que venia aplicando. Muchas gracias Daniel, gran trabajo.
Un saludo
Me gustaMe gusta
Excelente nota. Trabajo en Data Mining para el sector financiero y no dejo de pensar en la alta complementariedad que existe entre estos instrumentos y nuestras tradicionales herramientas econométricas. Cuando se trata de inferir relaciones causales, sin duda la robustez de la Econometría gana la partida (los «Furious Five», como los llama Angrist: Selección aleatoria, Regresión, Variables Instrumentales, diseño de regresiones discontínuas y diferencias en diferencias), pero a la hora de predecir, calcular asociaciones estadísticas o realizar un análisis descriptivo, sobre todo si no conocemos el modelo teórico que explica nuestros datos, todo el instrumental del data mining nos da un aporte valioso para captar patrones caoticos y altamente no lineales. Me alegra ver que investigadores serios comienzan a incorporarlo.
Saludos de un ex alumno.
Me gustaMe gusta
Muy interesante la aplicación y esta herramienta estadística que permite hallar los patrones de asociación entre variables objetivo. Es interesante como se desarrolla en estudios realizados sobre componentes químicos y aleaciones de alta pureza.
Me gustaMe gusta